常用类的hashCode与equals方法
常见类型的hashCode算法实现
第一章节我们了解到,java的Object类有hashCode,并且也介绍了默认的5种hashCode实现方式,下面我们来看看java中关于常见的对象hashCode实现(基本类型可以参见对应的包装类型)
- Boolean: true/false分别返回1231/1237这俩素数
1
2
3
4
5
6
7
public int hashCode() {
return Boolean.hashCode(value);
}
public static int hashCode(boolean value) {
return value ? 1231 : 1237;
}
- Byte/Short/Integer:
1
2
3
4
5
6
7
8
public int hashCode() {
return Byte.hashCode(value);
}
public static int hashCode(byte value) {
return (int)value;
}
- Float:
1
2
3
4
5
6
7
8
9
10
11
12
13
public static int hashCode(float value) {
return floatToIntBits(value);
}
public static int floatToIntBits(float value) {
if (!isNaN(value)) {
return floatToRawIntBits(value);
}
return 0x7fc00000;
}
public static native int floatToRawIntBits(float value);
- Double:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public int hashCode() {
return Double.hashCode(value);
}
public static int hashCode(double value) {
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
public static long doubleToLongBits(double value) {
if (!isNaN(value)) {
return doubleToRawLongBits(value);
}
return 0x7ff8000000000000L;
}
public static native long doubleToRawLongBits(double value);
- Long:
1
2
3
4
5
6
7
8
9
public int hashCode() {
return Long.hashCode(value);
}
public static int hashCode(long value) {
return (int)(value ^ (value >>> 32));
}
- String
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
// StringLatin1 的实现
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
// StringUTF16 的实现
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
可以看到,针对于byte/short/integer,hashcode即为值本身,float/double/long的计算稍微复杂一点,基本都是基于字节数组做一些运算,String hashCode计算稍显复杂一点,字节数组的值加上一个素数的多项式公式的幂次方构成。
java的hashCode返回的是一个int值,int的范围是-21亿到21亿之间,hash算法一般需要考虑几个点
- 速度尽可能的快.
- 尽量产生少的冲突,冲突过多的话,会导致很多数据经过hash计算后,hashcode一致,从而影响hash的查找效率
基于上述两点,通常情况下对于多项式幂的底数的选择是一件比较困难的事情,此处选择31基于上述两点做一些取舍,effective java也有相关提及,任何数乘以31可以被优化为 31*h = (32-1)*h = h<<5 -h,可以把乘法运算转换为移位和加法运算,我们知道,对于计算机而言,移位运算与加法运算的时间复杂度基本是同级的,乘法与除法相较于上述两类运算稍慢些,其实对应的可选素数还有17 (17*h = (16+1)*h = h<<4 + h>),单纯从数学的角度来讲,选择31可能并不是最合适的,计算机是一门理论与工程实践相结合的学科,这类优化提升对于cpu的指令运算速度有提升,下述代码是一个生成测试数据的示例代码,选了两组数做对比
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.RandomStringUtils;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StringHashDemo {
static int[] BASIC_NUMBERS = {7877,8689, 9421, 200329, 401113, 499691, 901177};
static int CNT = 10000;
static int GROUP = 20;
public static int calcHashCode(String str, int prime) {
char[] array = str.toCharArray();
int result = 0;
for (int i = 0; i < array.length; i++) {
result = result * prime + array[i];
}
return result;
}
public static void main(String[] args) throws Exception {
Map<String, StrValObject> data = buildMap();
for (int prime : BASIC_NUMBERS) {
buildData(data, prime);
}
outPutFile(data);
outPutFile2(data);
}
private static Map<String, StrValObject> buildMap() {
Map<String, StrValObject> result = Maps.newTreeMap();
int groupCount = CNT / 20;
for (int i = 0; i < GROUP; i++) {
for (int j = 0; j < groupCount; j++) {
String str = RandomStringUtils.randomAlphabetic(i);
result.put(str, new StrValObject());
}
}
return result;
}
private static void buildData(Map<String, StrValObject> mapData, int prime) {
for (Map.Entry<String, StrValObject> entry : mapData.entrySet()) {
String key = entry.getKey();
StrValObject value = entry.getValue();
int hash = calcHashCode(key, prime);
InnerStrValObj innerStrValObj = new InnerStrValObj(prime, hash);
value.getList().add(innerStrValObj);
}
}
private static void outPutFile(Map<String, StrValObject> map) throws Exception {
FileWriter fw = new FileWriter("/tmp/hash_code.csv", true);
BufferedWriter bw = new BufferedWriter(fw);
Stream<Integer> stream = Arrays.stream(BASIC_NUMBERS).boxed();
String header = "str," + stream.map(i -> "hash_code_" + i).collect(Collectors.joining(","));
bw.write(header);
bw.newLine();
for (Map.Entry<String, StrValObject> entry : map.entrySet()) {
String key = entry.getKey();
List<InnerStrValObj> list = entry.getValue().getList();
Collections.sort(list);
String row = key + "," + list.stream().map(obj -> obj.getHash() + "").collect(Collectors.joining(","));
bw.write(row);
bw.newLine();
}
bw.close();
}
private static void outPutFile2(Map<String, StrValObject> map) throws Exception {
List<BufferedWriter> writers = Lists.newArrayList();
for (int prime : BASIC_NUMBERS) {
FileWriter fw = new FileWriter("/tmp/hash_code/hash_code" + prime + ".csv", true);
BufferedWriter bw = new BufferedWriter(fw);
String header = "str,hash_code_" + prime;
bw.write(header);
bw.newLine();
writers.add(bw);
}
for (Map.Entry<String, StrValObject> entry : map.entrySet()) {
String key = entry.getKey();
List<InnerStrValObj> list = entry.getValue().getList();
for (int i = 0; i < list.size(); i++) {
InnerStrValObj innerStrValObj = list.get(i);
String row = String.format("%s,%s", key, innerStrValObj.getHash());
BufferedWriter bw = writers.get(i);
bw.write(row);
bw.newLine();
}
}
for (BufferedWriter bw : writers) {
bw.close();
}
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
class StrValObject {
private List<InnerStrValObj> list = Lists.newArrayList();
}
@Data
@AllArgsConstructor
class InnerStrValObj implements Comparable<InnerStrValObj> {
private int prime;
private int hash;
@Override
public int compareTo(InnerStrValObj o) {
if (prime == o.getPrime()) {
return 0;
} else if (prime < o.getPrime()) {
return -1;
} else {
return 1;
}
}
}
合并csv的python代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import pandas as pd
import os as os
BASE_TMP_DIE = '/tmp/hash_code/'
writer = pd.ExcelWriter('~/Desktop/hash_code_multiple_large_number.xlsx')
listdir = os.listdir(BASE_TMP_DIE)
for filename in listdir:
if os.path.isfile(BASE_TMP_DIE + filename):
sheetname = filename.split('.')[0]
csvfile = pd.read_csv(BASE_TMP_DIE + filename, encoding="utf8")
csvfile.to_excel(writer, sheet_name=sheetname)
else:
pass
writer.close()
生成的excel数据做了两套散点图,参考如下:
1
static int[] BASIC_NUMBERS = {7,10, 11, 24, 31, 37,41,48,61};
1
static int[] BASIC_NUMBERS = {7877,8689, 9421, 200329, 401113, 499691, 901177};
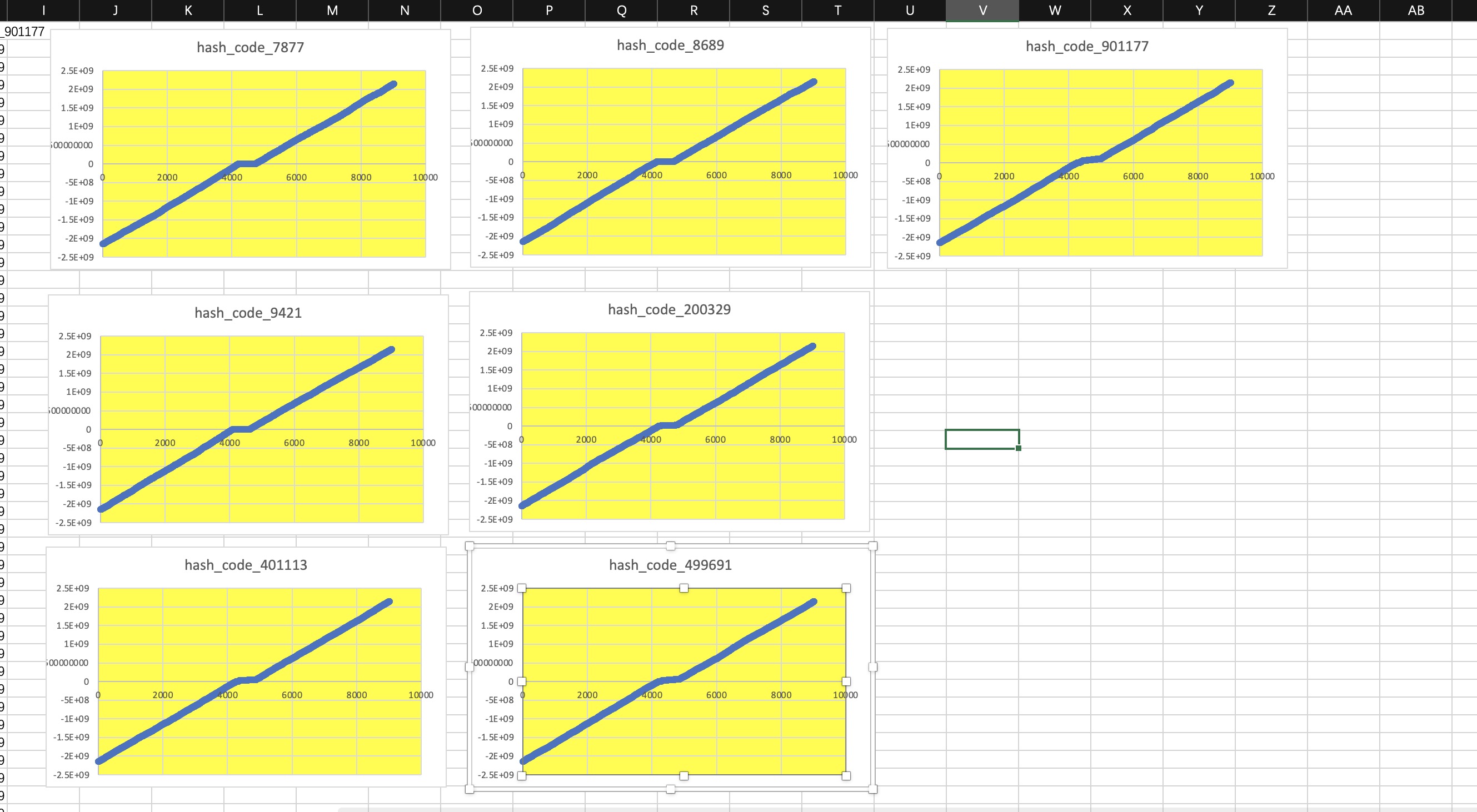
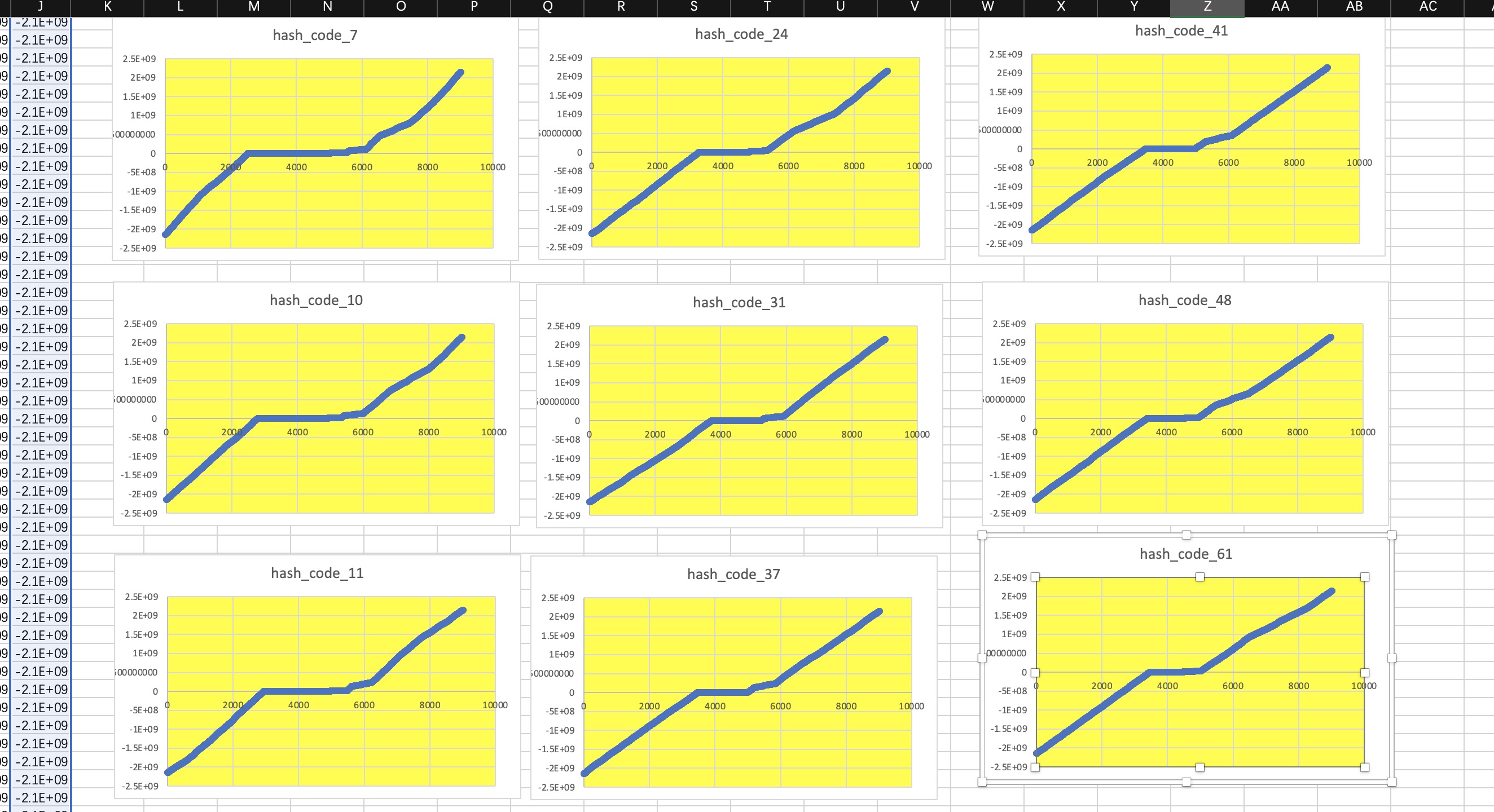
程序的整体逻辑生成10000个左右的随机数,数据一共20组,每组数据500个,重复数据会被过滤,整体样本数据大概9000+, 从第一张图可以看到基本每个数据都有一个比较平缓的线条区域,由于生成的hashcode区间比较广,图像的纵坐标的值的跨度范围比较大,平的那一部分不代表这部分数据相等,只是说明这部分数据的区间范围相对而言比较集中,集中的意思预示着这部分数据产生冲突的概率比较大,样本生成的数据是一样的,采样控制变量法,修改运算的基数,从而可以比较用哪个素数来生成hashCode比较合适
第二张图采用的是几个比较大的素数,可以看到生成的图像近似于一条直线,相较于第一张而言产生的冲突概率较小, hashCode值分布教均匀
为什么需要在重写equals的同时重写hashCode方法
从上一章节中我们知道equals与hashCode是object类的两个方法,在我们进行编码的时候, 如果判断两个对象相等,我们通常都会重写equals方法,常用的IDE都会检测到我们重写了equals方法的时候, 通常都会建议我们重些hashCode方法,我们看下述代码,不重写hashCode的情形:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Data
@AllArgsConstructor
public class ObjectWithOutHashCode {
private int id;
private String name;
@Override
public boolean equals(Object obj) {
if (obj == null || !(obj instanceof ObjectWithOutHashCode)) {
return false;
}
ObjectWithOutHashCode o = (ObjectWithOutHashCode) obj;
if (Objects.equals(name, this.getName())) {
return true;
}
return false;
}
public static void main(String[] args) {
ObjectWithOutHashCode obj1 = new ObjectWithOutHashCode(1, "test");
ObjectWithOutHashCode obj2 = new ObjectWithOutHashCode(2, "test");
System.out.println(obj1.hashCode() + "," + obj2.hashCode());
System.out.println("obj1 equals obj2:" + obj1.equals(obj2));
List<ObjectWithOutHashCode> list = Lists.newArrayList();
if (!list.contains(obj1)) {
list.add(obj1);
}
if (!list.contains(obj2)) {
list.add(obj2);
}
Set<ObjectWithOutHashCode> set = Sets.newHashSet(obj1, obj2);
System.out.println(list.size());
System.out.println(set.size());
}
}
针对上述代码,输出结果如下:
1
2
3
4
356473385,2136344592
obj1 equals obj2:true
1
2
可以看到没有覆写hashCode方法的对象,默认使用Object类的hashCode方法,两次new出来的对象hashCode不同,针对于equals方法返回true的情形, 集合接口ArrayList与HashSet的行为不太一致,可以参见ArrayList的add方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
return indexOfRange(o, 0, size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = elementData;
if (o == null) {
for (int i = start; i < end; i++) {
if (es[i] == null) {
return i;
}
}
} else {
for (int i = start; i < end; i++) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
可以看到针对对象不为空的情形,判断对象是否相等的方法使用的是equals,而HashSet的底层是基于HashMap实现,可以看看HashSet的add方法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 底层调用的是Map的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
可以看到上述代码在做add的时候,会先去拿对象的hashCode与底层数组的大小做运算,确定元素位于那个槽,倘若hashCode一样(hash冲突),进一步判断对象的equals方法是否相等,这两步相等则认为两个对象是同一个key,否则便是不同的key值了,这也能解释为什么上述list与set的元素个数不一致的原因
从上述代码对比我们可以看出,java的集合框架,涉及到底层需要进行hash计算的尽量同时重写这两个方法(除非你真的确认你的对象永远不会放进集合中,但是从程序的健壮性来考虑,重写后的hashCode与equals方法能使代码健壮性更好)。
对应的可以看看重写了hashCoe/equals方法的对象输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
@Data
@AllArgsConstructor
public class ObjectWithHashCode {
private int id;
private String name;
@Override
public boolean equals(Object obj) {
if (obj == null || !(obj instanceof ObjectWithHashCode)) {
return false;
}
ObjectWithHashCode o = (ObjectWithHashCode) obj;
if (Objects.equals(name, this.getName())) {
return true;
}
return false;
}
@Override
public int hashCode() {
return Objects.hash(name);
}
public static void main(String[] args) {
ObjectWithHashCode obj1 = new ObjectWithHashCode(1, "test");
ObjectWithHashCode obj2 = new ObjectWithHashCode(2, "test");
System.out.println("obj1 equals obj2:" + obj1.equals(obj2));
List<ObjectWithHashCode> list = Lists.newArrayList();
if (!list.contains(obj1)) {
list.add(obj1);
}
if (!list.contains(obj2)) {
list.add(obj2);
}
Set<ObjectWithHashCode> set = Sets.newHashSet(obj1, obj2);
System.out.println(list.size());
System.out.println(set.size());
}
}
输出:
1
2
3
obj1 equals obj2:true
1
1
so,为了程序少出bug,还是将equals与hashCode成对重写,Java7新增的Objects方法有相关的hash值计算方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// Objects.hash
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
// Arrays.hashCode
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
可以看到,Arrays中的hashCode素数选择用的也是31